宝塔屏蔽垃圾搜索引擎蜘蛛以及采集扫描工具教程
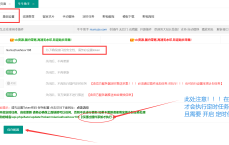
找到文件目录/www/server/nginx/conf文件夹,新建一个名为agent_deny.conf的文件(可自定义文件名),创建后点击编辑,将以下代码放入并保存。在【网站】-【设置】中,点击左侧【配置文件】选项卡,在第7-8行左右插入代码,保存后重启nginx。这样,蜘蛛或工具扫描网站时会提示403禁止访问。
找到文件目录/www/server/nginx/conf。在此目录下新建一个名为agent_deny.conf的文件。编辑该文件,将用于屏蔽垃圾搜索引擎蜘蛛和采集扫描工具的代码放入并保存。修改网站配置文件 登录宝塔面板,进入“网站”管理页面。选择需要设置的网站,点击“设置”。在左侧选项卡中点击“配置文件”。
您的网站被360搜索识别为垃圾网站或存在安全问题,例如恶意软件、钓鱼网站等,因此被标记为“不稳定”。建议您检查您的网站服务器的健康状态,并确保网站安全,排除以上可能导致问题的原因,同时也可以向360搜索提交申诉,解除对您的网站的标记。
网站一直没有蜘蛛来爬,能不能帮我看下到底问题在哪?
1、查看自己的域名以前的主人,看看域名以前是否做了违法的站点。如果是的话那么蜘蛛不爬是完全有道理的,就好比Maas以前论坛那个域名以前是做liuhecai站的。至今搜狗和谷歌蜘蛛压根没来过。
2、查看站内结构是否是安全的,如果有危险性的话蜘蛛是不会对其网站爬行的,一般蜘蛛识别网站不安全的是死站,因为死站容易生成死循环,如果蜘蛛掉进死循环也就是我们所说的蜘蛛陷阱的话就很难再爬行出来。
3、检查robots文件中是否有屏蔽对应的搜索引擎蜘蛛。如果robots中写入了禁止搜索引擎抓取,那么蜘蛛是不会抓取的。2:检查网站空间或服务器的地理位置。如果网站服务器空间在国外或相对偏远的国外,有可能爬虫有无法访问的情况。3:咨询空间服务商看是否对你所需要的蜘蛛做了屏蔽策略。
4、网站结构不利于蜘蛛爬行。 首页内容不丰富或者是采集内容过多。 域名存在被K的不良记录。 刚上线就急忙忙的做不恰当的优化,如把标题改来改去、页面调整、路径修改等。
5、快照长时间不更新并没有代表任何问题,你只需要关注是否网站流量突然下降,如果各方面指标都正常,蜘蛛频繁来访,只能代表你的页面质量较高,外部链接非常理想。
dedecms织梦蜘蛛来访记录插件
dedecms织梦蜘蛛来访记录插件是一款专为织梦CMS设计的后台功能扩展工具,主要用于直观记录和分析搜索引擎蜘蛛的爬行行为,帮助网站优化人员快速调整SEO策略。核心功能与优势简化蜘蛛记录查看流程 传统方式需下载服务器日志并使用分析工具,操作复杂且对新手不友好。
第四,网站首页有个随机抽取功能,每次刷新页面都会抽取不同的文章标题,蜘蛛每次来访时,都是不同的标题内容,每次都可以更新快照,使网站由不变而变,保持经常更新,增强关键词排名。
帝国cms生成地图在哪里
帝国CMS的网站地图生成功能位于后台管理 - 网站设置 - 网站地图,具体操作步骤如下:登录后台:进入帝国CMS后台管理系统,输入账号密码完成登录。进入网站设置:登录后,点击左侧菜单栏中的“网站设置”选项。找到网站地图功能:在“网站设置”页面中,定位并点击“网站地图”选项,进入网站地图管理界面。
帝国CMS的地图生成功能位于后台管理界面的“内容管理”→“地图生成”中。具体操作步骤及配置选项如下:步骤说明 登录后台管理界面:使用管理员账号登录帝国CMS系统。进入内容管理模块:在左侧菜单栏中找到并点击“内容管理”选项。
帝国CMS的sitemap.xml文件位于[帝国CMS安装路径]/e/data/sitemap.xml。以下是关于帝国CMS生成地图的详细信息:生成步骤登录后台:打开帝国CMS的后台管理页面,输入正确的用户名和密码进行登录。进入生成地图界面:登录成功后,在后台管理界面中,依次点击“系统管理”“生成管理”“生成地图”。
生成网站地图后台操作路径 登录帝国CMS后台,进入 “系统” → “数据更新” → “生成网站地图”。配置生成选项:内容模型:选择需包含的模型(如文章、图片、下载等)。生成路径:建议设置为根目录下的 sitemap.xml(如 https://)。
帝国CMS生成网站地图需使用“网站地图”插件,具体操作步骤如下:安装插件 登录帝国CMS后台管理界面,进入应用中心 推荐应用。在搜索框中输入“网站地图”,找到对应插件后点击安装,等待安装完成。启用插件 安装完成后,进入系统管理 应用管理。在应用列表中找到“网站地图”插件,点击启用按钮激活功能。
登录帝国CMS后台,进入 “扩展管理” → “插件管理”。找到地图插件,点击 “安装” 按钮完成安装。配置参数 安装后,在插件列表中找到该插件,点击 “配置” 进入设置页面。关键参数包括:生成频率:建议设置为 每周或每月一次(避免频繁生成增加服务器负担)。
如何阻止百度baidu爬虫和谷歌蜘蛛抓取网站内容
1、如果不希望百度或 Google抓取网站内容,就需要在服务器的根目录中放入一个 robots.txt 文件,其内容如下:User-Agent: *Disallow: / 这是大部份网络漫游器都会遵守的标准协议,加入这些协议后,它们将不会再漫游您的网络服务器或目录。
2、在网站的根目录下上传robots文件;禁止百度抓取网站所有页面。
3、找到文件目录/www/server/nginx/conf文件夹,新建一个名为agent_deny.conf的文件(可自定义文件名),创建后点击编辑,将以下代码放入并保存。在【网站】-【设置】中,点击左侧【配置文件】选项卡,在第7-8行左右插入代码,保存后重启nginx。这样,蜘蛛或工具扫描网站时会提示403禁止访问。
")
如何屏蔽蜘蛛抓取
1、若不希望在网站日志中出现MJ12bot蜘蛛的访问记录,可直接在robots.txt文件中将其屏蔽。由于MJ12bot蜘蛛遵循robots协议,此操作即可实现对其的屏蔽。
2、直接过滤蜘蛛/机器人的IP段。SEO优化图片有哪些方法?图片优化要做上alt属性 图片大小要统一 图片的水印处理 要上传清晰的图片 没有必要优化你网站上的所有的图片。比如模板中使用的图片、导航中的图片还有背景图片等等,我们不用为这些图片添加ALT标签,我们可以把这些图片放在一个单独的文件夹里。
3、联系百度管理人员,信箱地址为:webmaster@baidu.com,用网站联系人信箱发电邮,如实说明删除网页快照的情况,经百度核实后,网页停止收录抓取。登陆百度自己的“百度快照”帖吧和“百度投诉”帖吧,发个帖子,表明删除网页收录网站快照的原因,当百度管理人员,看到会给予处理。
4、要确保网站某些目录或页面不被收录,需要正确使用 robots 文件或Meta Robots 标签来实现网站的禁止收录机制。robots 文件 搜索引擎蜘蛛访问网站时,会先查看网站根目录下有没有一个命名为 robots.txt 的纯文本文件,它的主要作用是制定搜索引擎抓取或者禁止网站的某些内容。